Определить распределение случайной величины. Закон распределения случайных величин
Рассмотрим дискретные распределения, которые часто используются при моделировании систем сервиса.
Распределение Бернулли. Схемой Бернулли называется последовательность независимых испытаний, в каждом из которых возможны лишь два исхода - «успех» и «неудача» с вероятностями р и q = 1 - р. Пусть случайная переменная X может принимать два значения с соответствующими вероятностями:
Функция распределения Бернулли имеет вид
Ее график показан на рис. 11.1.
Случайная величина с таким распределением равна числу успехов в одном испытании схемы Бернулли.
Производящая функция, согласно (11.1) и (11.15), вычисляется как
Рис. 11.1.

По формуле (11.6) найдем математическое ожидание распределения:
Вычислим вторую производную производящей функции по (11.17)
По (11.7) получим дисперсию распределения
Распределение Бернулли играет большую роль в теории массового сервиса, являясь моделью любого случайного эксперимента, исходы которого принадлежат двум взаимно исключающим классам.
Геометрическое распределение. Предположим, что события происходят в дискретные моменты времени независимо друг от друга. Вероятность того, что событие произойдет, равна р, а вероятность того, что оно не произойдет, q = 1-р, например пришедший клиент делает заказ.
Обозначим через р к вероятность того, что событие произойдет 1-й раз в момент к, т.е. к -й клиент сделал заказ, а предыдущие к- 1 клиентов нет. Тогда вероятность этого сложного события можно определить по теореме умножения вероятностей независимых событий
Вероятности событий при геометрическом распределении показаны на рис. 11.2.
Сумма вероятностей всех возможных событий
представляет собой геометрическую прогрессию, поэтому распределение и называется геометрическим. Так как (1 - р)

Случайная величина Хс геометрическим распределением имеет смысл номера первого успешного испытания в схеме Бернулли.

Рис. 11.2.
Определим вероятность того, что событие произойдет для Х>к

и функцию геометрического распределения

Вычислим производящую функцию геометрического распределения по (11.1) и (11.20)
математическое ожидание геометрического распределения по (11.6)
а дисперсию по (11.7)

Геометрическое распределение считается дискретной версией непрерывного экспоненциального распределения и также обладает рядом свойств, полезных для моделирования систем сервиса. В частности, как экспоненциальное распределение, геометрическое не имеет памяти:

т.е. если проведено / неуспешных опытов, тогда вероятность того, что для первого успеха необходимо провести еще j новых опытов, такая же, как вероятность того, что при новой серии испытаний для первого успеха необходимо провести./"опытов. Другими словами, предыдущие опыты не оказывают эффекта на будущие опыты и опыты являются независимыми. Часто это соответствует действительности. Например, клиенты независимы и заказы делают случайным образом.
Рассмотрим пример системы, параметры функционирования которой подчиняются геометрическому распределению.
В распоряжении мастера имеется п однотипных запасных деталей. Каждая деталь с вероятностью q имеет дефект. При ремонте деталь устанавливается в устройство, которое проверяется на работоспособность. Если устройство не работает, то деталь заменяется на другую. Рассматривается случайная величина X - число деталей, которые будут проверены.
Вероятности числа проверенных деталей будут иметь значения, показанные в таблице:
|
ря"~ х |
Здесь q = 1 - р.
Математическое ожидание числа проверенных деталей определяется как

Биномиальное распределение. Рассмотрим случайную величину
где Xj подчиняется распределению Бернулли с параметром р и случайные величины Xj независимы.
Значение случайной величины X будет равно числу появления единиц при п испытаниях, т.е. случайная величина с биномиальным распределением имеет смысл числа успехов в п независимых испытаниях.
Согласно (11.9), производящая функция суммы взаимно независимых случайных величин, каждая из которых имеет распределение Бернулли, равна произведению их производящих функций (11.17):
Раскладывая производящую функцию (11.26) в ряд, получим

В соответствии с определением производящей функции (11.1) вероятность того, что случайная величина X примет значение к:
где
 - биномиальные коэффициенты.
- биномиальные коэффициенты.
11оскольку & единиц на п местах можно расположить С* способами, то число выборок, содержащих к единиц, будет, очевидно, таким же.
Функция распределения для биномиального закона вычисляется по формуле
Распределение называется биномиальным в связи с тем, что вероятности по форме представляют собой члены разложения бинома:

Ясно, что суммарная вероятность всех возможных исходов равна 1:

Из (11.29) можно получить ряд полезных свойств биномиальных коэффициентов. Например, при р =1, q =1 получим
Если положить р =1, q = - 1 , то
При любом 1к справедливы следующие соотношения:
Вероятности того, что в п
испытаниях событие наступит: 1) менее &раз; 2) более к
раз; 3) не менее &раз; 4) не более &раз, находят соответственно по формулам:

Используя (11.6), определим математическое ожидание биномиального распределения
а по (11.7) - дисперсию:

Рассмотрим несколько примеров систем, параметры функционирования которых описываются биномиальным распределением.
1. Партия из 10 продуктов содержит один нестандартный. Найдем вероятность того, что при случайной выборке 5 продуктов все они будут стандартными (событие А).
Число всех случайных выборок п - С , э 0 , а число выборок, благоприятствующих событию, есть п = С 9 5 . Таким образом, искомая вероятность равна

2. При въезде в новую квартиру в осветительную сеть было включено 2к новых электрических ламп. Каждая электрическая лампа в течение года перегорает с вероятностью р. Найдем вероятность того, что в течение года не менее половины первоначально включенных ламп придется заменить новыми (событие А):

3. Человек, принадлежащий к определенной группе потребителей, с вероятностью 0,2 предпочитает продукт 1, с вероятностью 0,3 - продукт 2, с вероятностью 0,4 - продукт 3, с вероятностью 0,1 - продукт 4. Выбрана наугад группа из 6 потребителей. Найдем вероятности следующих событий: А - в составе группы находятся не менее 4 потребителей, предпочитающих продукт 3; В- в составе группы находится хотя бы один потребитель, предпочитающий продукт 4.
Эти вероятности равны:
При больших/? вычисления вероятностей становятся громоздкими, поэтому используют предельные теоремы.
Локальная теорема Лапласа , согласно которой вероятность Р п (к) определяется формулой
где
 - функция Гаусса;
- функция Гаусса;

Интегральная теорема Лапласа используется для вычисления вероятности того, что в п независимых испытаниях событие наступит не менее к { раз и не более к 2 раз:
Рассмотрим примеры использования данных теорем.
1. Швейная мастерская производит пошив одежды по индивидуальному заказу, среди которой 90 % высшего качества. Найдем вероятность того, что среди 200 изделий будет высшего качества не меньше 160 и не больше 170.
Решение:

2. У страховой компании имеется 12 тыс. клиентов. Каждый из них, страхуясь от несчастного случая, вносит 10 тыс. руб. Вероятность несчастного случая р - 0,006, а выплата пострадавшему 1 млн руб. Найдем прибыль страховой компании, обеспечиваемую с вероятностью 0,995; иными словами, на какую прибыль может рассчитывать страховая компания при уровне риска 0,005.
Решение: Суммарный взнос всех клиентов 12 000-10 000 = 120 млн руб. Прибыль Якомпании зависит от числа к несчастных случаев и определяется равенством Я = 120 000-1000/: тыс. руб.
Следовательно, надо найти такое число Л/, чтобы вероятность события Р(к > М) не превосходила 0,005. Тогда с вероятностью 0,995 будет обеспечена прибыль Я =120000-10004/ тыс. руб.
Неравенство Р(к > М) Р(к0,995. Так как к > 0, то Р(0 0,995. Для оценки этой вероятности воспользуемся интегральной теоремой Лапласа при п- 12 000 и/?=0,006, #=0,994:

Так как*! F(x ]) = -0,5.
Таким образом, необходимо найти Л/, при котором
Находим (М - 72)/8,5 > 2,58. Следовательно, М>12 + 22 = 94.
Итак, с вероятностью 0,995 компания гарантирует прибыль
Часто требуется определить наивероятнейшее число к 0 . Вероятность наступления события с числом успехов к 0 превышает или по крайней мере не меньше вероятности остальных возможных исходов испытаний. Наивероятнейшее число к 0 определяют из двойного неравенства
3. Пусть имеется 25 образцов средств потребления. Вероятность того, что каждый из образцов будет приемлем для клиента, равна 0,7. Необходимо определить наиболее вероятное число образцов, которые окажутся приемлемыми для клиентов. По (11.39)

Отсюда к 0 - 18.
Распределение Пуассона. Распределение Пуассона определяет вероятность того, что при очень большом числе испытаний п, в каждом из которых вероятность события р очень мала, событие наступит ровно к щз.
Пусть произведение пр = к; это означает, что среднее число появления события в различных сериях испытаний, т.е. при различных п, остается неизменным. В этом случае распределение Пуассона может использоваться для аппроксимации биномиального распределения:

Так как для больших п

Производящая функция распределения Пуассона вычисляется по (11.1) как
где по формуле Маклорена
В соответствии со свойством коэффициентов производящей функции вероятность появления к успехов при среднем числе успехов X вычисляется как (11.40).
На рис. 11.3 показана плотность вероятности распределения Пуассона.
Производящую функцию распределения Пуассона можно также получить, воспользовавшись разложением в ряд производящей функции биномиального распределения для пр = Х при п -» оо и формулой Маклорена (11.42):

Рис. 11.3.
Определим математическое ожидание по (11.6)
а дисперсию по (11.7)

Рассмотрим пример системы с пуассоновским распределением параметров.
Предприятие отправило в магазин 500 изделий. Вероятность повреждения изделия в пути равна 0,002. Найти вероятности того, что в пути будет повреждено изделий: ровно 3 (событие Я); менее 3 (событие В) более 3 (событие Q; хотя бы одно (событие D).
Число п = 500 велико, вероятность р = 0,002 мала, рассматриваемые события (повреждение изделий) независимы, поэтому можно использовать формулу Пуассона (11.40).
При X = пр = 500 0,002=1 получим:

Распределение Пуассона обладает рядом полезных для моделирования систем сервиса свойств.
1. Сумма случайных переменных Х= Х { + Х 2 с пуассоновским распределением также распределена по закону Пуассона.
Если случайные переменные имеют производящие функции:
то, согласно (11.9), производящая функция суммы независимых случайных переменных с пуассоновским распределением будет иметь вид:
Параметр результирующего распределения равен Х х + Х 2 .
2. Если число элементов./V множества подчиняется пуассоновскому распределению с параметром X и каждый элемент выбирается независимо с вероятностью р, тогда элементы выборки размером Y распределены по закону Пуассона с параметром рХ.
Пусть
![]() , где
, где
![]() отвечает распределению Бернулли, а N
- распределению Пуассона. Соответствующие производящие функции, согласно (11.17), (11.41):
отвечает распределению Бернулли, а N
- распределению Пуассона. Соответствующие производящие функции, согласно (11.17), (11.41):
Производящая функция случайной переменной Y вычисляется в соответствии с (11.14)
т.е. производящая функция соответствует распределению Пуассона с параметром рХ.
3. Как следствие свойства 2 справедливо следующее свойство. Если число элементов ^множества распределено по закону Пуассона с параметром X и множество случайным образом распределяется с вероятностями /?, и р 2 = 1 - Р на две группы, тогда размеры множеств 7V, и N 2 независимы и распределены по Пуассону с параметрами р{к и р{к.
Для удобства использования представим полученные результаты относительно дискретных распределений в виде табл. 11.1 и 11.2.
Таблица 11.1. Основные характеристики дискретных распределений
|
Распределение |
Плотность |
Диапазон |
Параметры |
tn | |
С Х --2 |
|
|
Бернулли |
Р{Х = } = р Р {X = 0} = Р + Я = 1 |
п - 0,1 |
||||
|
Геометрическое |
р(-р) к - 1 |
к = 1,2,... |
^ 1 1 |тз |
1 -р |
||
|
Биномиальное |
с к р к (- Р г к |
* = 1,2,...,#» |
пр{ - р) |
1 -р пр |
||
|
Пуассона |
Е -х к ! |
к = 1,2,... |
Табл и ца 11. 2. Производящие функции дискретных распределений
КОНТРОЛЬНЫЕ ВОПРОСЫ
- 1. Какие распределения вероятностей относят к дискретным?
- 2. Что такое производящая функция и для чего оно используется?
- 3. Как вычислить моменты случайных величин с использованием производящей функции?
- 4. Чему равна производящая функция суммы независимых случайных величин?
- 5. Что называется составным распределением и как вычисляются производящие функции составных распределений?
- 6. Дайте основные характеристики распределения Бернулли, приведите пример использования в задачах сервиса.
- 7. Дайте основные характеристики геометрического распределения, приведите пример использования в задачах сервиса.
- 8. Дайте основные характеристики биномиального распределения, приведите пример использования в задачах сервиса.
- 9. Дайте основные характеристики распределения Пуассона, приведите пример использования в задачах сервиса.
Во многих задачах, связанных с нормально распределенными случайными величинами, приходится определять вероятность попадания случайной величины , подчиненной нормальному закону с параметрами , на участок от до . Для вычисления этой вероятности воспользуемся общей формулой
где - функция распределения величины .
Найдем функцию распределения случайной величины , распределенной по нормальному закону с параметрами . Плотность распределения величины равна:
 .
(6.3.2)
.
(6.3.2)
Отсюда находим функцию распределения
 . (6.3.3)
. (6.3.3)
Сделаем в интеграле (6.3.3) замену переменной
и приведем его к виду:
 (6.3.4)
(6.3.4)
Интеграл (6.3.4) не выражается через элементарные функции, но его можно вычислить через специальную функцию, выражающую определенный интеграл от выражения или (так называемый интеграл вероятностей), для которого составлены таблицы. Существует много разновидностей таких функций, например:
 ;
;

и т.д. Какой из этих функций пользоваться – вопрос вкуса. Мы выберем в качестве такой функции
 . (6.3.5)
. (6.3.5)
Нетрудно видеть, что эта функция представляет собой не что иное, как функцию распределения для нормально распределенной случайной величины с параметрами .
Условимся называть функцию нормальной функцией распределения. В приложении (табл. 1) приведены таблицы значений функции .
Выразим функцию распределения (6.3.3) величины с параметрами и через нормальную функцию распределения . Очевидно,
![]() .
(6.3.6)
.
(6.3.6)
Теперь найдем вероятность попадания случайной величины на участок от до . Согласно формуле (6.3.1)
Таким образом, мы выразили вероятность попадания на участок случайной величины , распределенной по нормальному закону с любыми параметрами, через стандартную функцию распределения , соответствующую простейшему нормальному закону с параметрами 0,1. Заметим, что аргументы функции в формуле (6.3.7) имеют очень простой смысл: есть расстояние от правого конца участка до центра рассеивания, выраженное в средних квадратических отклонениях; - такое же расстояние для левого конца участка, причем это расстояние считается положительным, если конец расположен справа от центра рассеивания, и отрицательным, если слева.
Как и всякая функция распределения, функция обладает свойствами:
3. - неубывающая функция.
Кроме того, из симметричности нормального распределения с параметрами относительно начала координат следует, что
Пользуясь этим свойством, собственно говоря, можно было бы ограничить таблицы функции только положительными значениями аргумента, но, чтобы избежать лишней операции (вычитание из единицы), в таблице 1 приложения приводятся значения как для положительных, так и для отрицательных аргументов.

На практике часто встречается задача вычисления вероятности попадания нормально распределенной случайной величины на участок, симметричный относительно центра рассеивания . Рассмотрим такой участок длины (рис. 6.3.1). Вычислим вероятность попадания на этот участок по формуле (6.3.7):
Учитывая свойство (6.3.8) функции и придавая левой части формулы (6.3.9) более компактный вид, получим формулу для вероятности попадания случайной величины, распределенной по нормальному закону на участок, симметричный относительно центра рассеивания:
![]() .
(6.3.10)
.
(6.3.10)
Решим следующую задачу. Отложим от центра рассеивания последовательные отрезки длиной (рис. 6.3.2) и вычислим вероятность попадания случайной величины в каждый из них. Так как кривая нормального закона симметрична, достаточно отложить такие отрезки только в одну сторону.

По формуле (6.3.7) находим:
 (6.3.11)
(6.3.11)
Как видно из этих данных, вероятности попадания на каждый из следующих отрезков (пятый, шестой и т.д.) с точностью до 0,001 равны нулю.
Округляя вероятности попадания в отрезки до 0,01 (до 1%), получим три числа, которые легко запомнить:
0,34; 0,14; 0,02.
Сумма этих трех значений равна 0,5. Это значит, что для нормально распределенной случайной величины все рассеивания (с точностью до долей процента) укладывается на участке .
Это позволяет, зная среднее квадратическое отклонение и математическое ожидание случайной величины, ориентировочно указать интервал её практически возможных значений. Такой способ оценки диапазона возможных значений случайной величины известен в математической статистике под названием «правило трех сигма». Из правила трех сигма вытекает также ориентировочный способ определения среднего квадратического отклонения случайной величины: берут максимальное практически возможное отклонение от среднего и делят его на три. Разумеется, этот грубый прием может быть рекомендован, только если нет других, более точных способов определения .
Пример 1. Случайная величина , распределенная по нормальному закону, представляет собой ошибку измерения некоторого расстояния. При измерении допускается систематическая ошибка в сторону завышения на 1,2 (м); среднее квадратическое отклонения ошибки измерения равно 0,8 (м). Найти вероятность того, что отклонение измеренного значения от истинного не превзойдет по абсолютной величине 1,6 (м).
Решение. Ошибка измерения есть случайная величина , подчиненная нормальному закону с параметрами и . Нужно найти вероятность попадания этой величины на участок от до . По формуле (6.3.7) имеем:
Пользуясь таблицами функции (приложение, табл. 1), найдем:
![]() ;
,
;
,
Пример 2. Найти ту же вероятность, что и в предыдущем примере, но при условии, что систематической ошибки нет.
Решение. По формуле (6.3.10), полагая , найдем:
![]() .
.
Пример 3. По цели, имеющей вид полосы (автострада), ширина которой равна 20 м, ведется стрельба в направлении, перпендикулярном автостраде. Прицеливание ведется по средней линии автострады. Среднее квадратическое отклонение в направлении стрельбы равно м. Имеется систематическая ошибка в направлении стрельбы: недолет 3 м. Найти вероятность попадания в автостраду при одном выстреле.
Определение 3. Х имеет нормальный закон распределения (закон Гаусса), если ее плотность распределения имеет вид:
где m = M (X ), σ 2 = D (X ), σ > 0 .
Кривую нормального закона распределения называют нормальной или гауссовой кривой (рис. 6.7).
Нормальная кривая симметрична относительно прямой х = m , имеет максимум в точке х = m , равный .
Функция распределения случайной величины Х, распределенной по нормальному закону, выражается через функцию Лапласа Ф(х ) по формуле:
Ф(x ) – функция Лапласа.
Замечание. Функция Ф(х ) является нечетной (Ф(-х ) = -Ф(х )), кроме того, при х > 5 можно считать Ф(х ) ≈ 1/2.
Таблица значений функции Ф(х ) приведена в приложении (табл. П 2.2).
График функции распределения F (x ) изображен на рис. 6.8.
Вероятность того, что случайная величина Х примет значения, принадлежащие интервалу (a;b ) вычисляются по формуле:
Р (a < Х < b ) = .
Вероятность того, что абсолютная величина отклонения случайной величины от ее математического ожидания меньше положительного числа δ вычисляется по формуле:
P (| X - m| .
В частности, при m =0 справедливо равенство:
P (| X| .
"Правило трех сигм"
Если случайная величина Х имеет нормальный закон распределения с параметрами m и σ, то практически достоверно, что ее значения заключены в интервале (m 3σ; m + 3σ), так как P (| X - m| = 0,9973.
Задача 6.3. Случайная величина Х распределена нормально с математическим ожиданием 32 и дисперсией 16. Найти: а) плотность распределения вероятностей f (x ); Х примет значение из интервала (28;38).
Решение: По условию m = 32, σ 2 = 16, следовательно, σ= 4, тогда
а)
б) Воспользуемся формулой:
Р (a< Х)= .
Подставив a = 28, b = 38, m = 32, σ= 4, получим
Р (28< Х< 38)= Ф(1,5) Ф(1)
По таблице значений функции Ф(х ) находим Ф(1,5) = 0,4332, Ф(1) = 0,3413.
Итак, искомая вероятность:
P
(28 Задачи
6.1.
Случайная величина Х
равномерно распределена в интервале (-3;5). Найдите: а) плотность распределения f
(x
);
б) функции распределения F
(x
);
в) числовые характеристики; г) вероятность Р
(4<х
<6). 6.2.
Случайная величина Х
равномерно распределена на отрезке . Найдите: а) плотность распределения f
(x
);
б) функцию распределения F
(x
);
в) числовые характеристики; г) вероятность Р
(3≤х
≤6). 6.3.
На шоссе установлен автоматический светофор, в котором 2 минуты для транспорта горит зеленый свет, 3 секунды - желтый и 30 секунд - красный и т.д. Машина проезжает по шоссе в случайный момент времени. Найти вероятность того, что машина проедет мимо светофора, не останавливаясь. 6.4.
Поезда метрополитена идут регулярно с интервалом 2 минуты. Пассажир выходит на платформу в случайный момент времени. Какова вероятность того, что ждать поезд пассажиру придется больше 50 секунд. Найти математическое ожидание случайной величины Х
- время ожидания поезда. 6.5.
Найти дисперсию и среднее квадратическое отклонение показательного распределения, заданного функцией распределения: 6.6.
Непрерывная случайная величина Х
задана плотностью распределения вероятностей: а) Назовите закон распределения рассматриваемой случайной величины. б) Найдите функцию распределения F
(x
) и числовые характеристики случайной величины Х
. 6.7.
Случайная величина Х
распределена по показательному закону, заданному плотностью распределения вероятностей: Х
примет значение из интервала (2,5;5). 6.8.
Непрерывная случайная величина Х
распределена по показательному закону, заданному функцией распределения: Найти вероятность того, что в результате испытания Х
примет значение из отрезка . 6.9.
Математическое ожидание и среднее квадратическое отклонение нормально распределенной случайной величины соответственно равны 8 и 2. Найдите: а) плотность распределения f
(x
); б) вероятность того, что в результате испытания Х
примет значение из интервала (10;14). 6.10.
Случайная величина Х
распределена нормально с математическим ожиданием 3,5 и дисперсией 0,04. Найдите: а) плотность распределения f
(x
); б) вероятность того, что в результате испытания Х
примет значение из отрезка . 6.11.
Случайная величина Х
распределена нормально с M
(X
) =
0 и D
(X
)=
1. Какое из событий: |Х
|≤0,6 или |Х
|≥0,6 имеет большую вероятность? 6.12.
Случайная величина Х
распределена нормально с M
(X
) =
0 и D
(X
)=
1.Из какого интервала (-0,5; -0,1) или (1; 2) при одном испытании она примет значение с большей вероятностью? 6.13.
Текущая цена за одну акцию может быть смоделирована с помощью нормального закона распределения с M
(X
)=
10 ден. ед. и σ(Х
) = 0,3 ден. ед. Найти: а) вероятность того, что текущая цена акции будет от 9,8 ден. ед. до 10,4 ден. ед.; б) с помощью "правила трех сигм" найти границы, в которых будет находиться текущая цена акции. 6.14.
Производится взвешивание вещества без систематических ошибок. Случайные ошибки взвешивания подчинены нормальному закону со средним квадратическим отклонением σ= 5г. Найти вероятность того, что в четырех независимых опытах ошибка при трех взвешиваниях не превзойдет по абсолютной величине 3 г. 6.15.
Случайная величина Х
распределена нормально с M
(X)=
12,6. Вероятность попадания случайной величины в интервал (11,4; 13,8) равна 0,6826. Найдите среднее квадратическое отклонение σ. 6.16.
Случайная величина Х
распределена нормально с M
(X
) = 12 и D
(X
) = 36. Найти интервал, в который с вероятностью 0,9973 попадет в результате испытания случайная величина Х
. 6.17.
Деталь, изготовленная автоматом, считается бракованной, если отклонение Х
ее контролируемого параметра от номинала превышает по модулю 2 единицы измерения. Предполагается, что случайная величина Х
распределена нормально с M
(X
) = 0 и σ(Х
) = 0,7. Сколько процентов бракованных деталей выдает автомат? 3.18.
Параметр Х
детали распределен нормально с математическим ожиданием 2, равным номиналу, и средним квадратическим отклонением 0,014. Найти вероятность того, что отклонение Х
от номинала по модулю не превысит 1 % номинала. Ответы
в) M
(X
)=1, D
(X
)=16/3, σ(Х
)= 4/ , г)1/8. в) M
(X
)=4,5, D
(X
) =2 , σ (Х
)= , г)3/5. 6.3.
40/51. 6.4.
7/12, M
(X
)=1. 6.5.
D
(X
) = 1/64, σ (Х
)=1/8 6.6.
M
(X
)=1 , D
(X
) =2 , σ (Х
)= 1 . 6.7.
Р(2,5<Х
<5)=е
-1 е
-2 ≈0,2325 6.8.
Р(2≤Х
≤5)=0,252. б) Р
(10 < Х
< 14) ≈ 0,1574. б) Р
(3,1 ≤ Х
≤ 3,7) ≈ 0,8185. 6.11.
|x
|≥0,6. 6.12.
(-0,5; -0,1). 6.13.
а) Р(9,8 ≤ Х ≤ 10,4) ≈ 0,6562 6.14.
0,111. б) (9,1; 10,9). 6.15.
σ = 1,2. 6.16.
(-6; 30). 6.17.
0,4 %. Примерами случайных величин, распределённых по нормальному закону, являются рост человека,
масса вылавливаемой рыбы одного вида
. Нормальность распределения означает следующее
: существуют значения
роста человека, массы рыбы одного вида, которые на интуитивном уровне воспринимаются как "нормальные"
(а по сути - усреднённые), и они-то в достаточно большой выборке встречаются гораздо чаще, чем
отличающиеся в бОльшую или меньшую сторону. Нормальное распределение вероятностей непрерывной случайной величины (иногда -
распределение Гаусса) можно назвать колоколообразным из-за того, что симметричная относительно среднего
функция плотности этого распределения очень похожа на разрез колокола (красная кривая на рисунке выше). Вероятность встретить в выборке те или иные значение равна
площади фигуры под кривой и в случае нормального распределения мы видим, что под верхом "колокола",
которому соответствуют значения, стремящиеся к среднему, площадь, а значит, вероятность, больше, чем под
краями. Таким образом, получаем то же, что уже сказано: вероятность встретить человека "нормального" роста,
поймать рыбу "нормальной" массы выше, чем для значений, отличающихся в бОльшую или меньшую сторону.
В очень многих случаях практики ошибки измерения распределяются по закону, близкому к нормальному. Остановимся ещё раз на рисунке в начале урока, на котором представлена функция плотности нормального распределения.
График этой функции получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA
. На ней
столбцы гистограммы представляют собой интервалы значений выборки, распределение которых близко (или, как принято говорить в
статистике, незначимо отличаются от) к собственно графику функции плотности нормального распределения, который
представляет собой кривую красного цвета. На графике видно, что эта кривая действительно колоколообразная. Нормальное распределение во многом ценно благодаря тому, что зная только математическое
ожидание непрерывной случайной величины и стандартное отклонение, можно вычислить любую вероятность, связанную
с этой величиной. Нормальное распределение имеет ещё и то преимущество, что один из наиболее простых
в использовании статистических критериев, используемых для проверки статистических гипотез - критерий
Стьюдента
- может быть использован только в том случае, когда данные выборки подчиняются нормальному
закону распределения. Функцию плотности нормального распределения непрерывной случайной величины
можно найти по формуле: где x
- значение изменяющейся величины, -
среднее значение, -
стандартное отклонение, e
=2,71828... - основание натурального логарифма, =3,1416... Свойства функции плотности нормального распределения
Изменения среднего значения перемещают кривую функции плотности нормального распределения
в направлении оси Ox
. Если
возрастает, кривая перемещается вправо, если
уменьшается, то влево. Если меняется стандартное отклонение, то меняется высота вершины кривой. При увеличении
стандартного отклонения вершина кривой находится выше, при уменьшении - ниже. Уже в этом параграфе начнём решать практические задачи, смысл которых обозначен в
заголовке. Разберём, какие возможности для решения задач предоставляет
теория. Отправное понятие для вычисления вероятности попадания нормально распределённой
случайной величины в заданный интервал - интегральная функция нормального распределения. Интегральная функция нормального распределения
: Однако проблематично получить таблицы для каждой возможной комбинации среднего и
стандартного отклонения. Поэтому одним из простых способов вычисления вероятности попадания нормально
распределённой случайной величины в заданный интервал является использование таблиц вероятностей для
стандартизированного нормального распределения. Стандартизованным или нормированным называется нормальное распределение
, среднее
значение которого , а
стандартное отклонение . Функция плотности стандартизованного нормального распределения
: Интегральная функция стандартизованного нормального распределения
: На рисунке ниже представлена интегральная функция стандартизованного нормального
распределения, график которой
получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA
. Собственно график
представляет собой кривую красного цвета, а значения выборки приближаются к нему. Для увеличения рисунка можно щёлкнуть по нему левой кнопкой мыши. Стандартизация случайной величины означает переход от первоначальных единиц,
используемых в задании, к стандартизованным единицам. Стандартизация выполняется по формуле На практике все возможные значения случайной величины часто не известны, поэтому
значения среднего и
стандартного отклонения
точно определить нельзя. Их заменяют средним арифметическим наблюдений и
стандартным отклонением s
. Величина z
выражает отклонения значений случайной величины
от среднего арифметического при измерении стандартных отклонений. Таблица вероятностей для стандартизированного нормального распределения, которая есть
практически в любой книге по статистике, содержит вероятности того, что имеющая стандартное нормальное
распределение случайная величина Z
примет значение меньше некоторого числа z
. То есть
попадёт в открытый интервал от минус бесконечности до z
. Например, вероятность того, что
величина Z
меньше 1,5, равна 0,93319. Пример 1.
Предприятие производит детали, срок службы которых
нормально распределён со средним значением 1000 и стандартным отклонением 200 часов. Для случайно отобранной детали вычислить вероятность того, что её срок службы будет
не менее 900 часов. Решение. Введём первое обозначение: Искомая вероятность. Значения случайной величины находятся в открытом интервале. Но мы умеем вычислять
вероятность того, что случайная величина примет значение, меньшее заданного, а по условию задачи требуется
найти равное или большее заданного. Это другая часть пространства под кривой плотности нормального распределения
(колокола). Поэтому, чтобы найти искомую вероятность, нужно из единицы вычесть упомянутую вероятность того,
что случайная величина примет значение, меньше заданного 900: Теперь случайную величину нужно стандартизировать. Продолжаем вводить обозначения: z
= (X
≤ 900)
; x
= 900
- заданное значение случайной величины; μ
= 1000
- среднее значение; σ
= 200
- стандартное отклонение. По этим данным условия задачи получаем: По таблицам стандартизированной случайной величине (границе интервала)
z
= −0,5
соответствует вероятность 0,30854. Вычтем
ее из единицы и получим то, что требуется в условии задачи: Итак, вероятность того, что срок службы детали будет не менее 900 часов, составляет
69%. Эту вероятность можно получить, используя функцию MS Excel НОРМ.РАСП (значение интегральной величины - 1): P
(X
≥900) = 1 - P
(X
≤900) = 1 - НОРМ.РАСП(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915. О расчётах в MS Excel - в одном из последующих параграфах этого урока. Пример 2.
В некотором городе среднегодовой доход семьи является
нормально распределённой случайной величиной со средним значением 300000 и стандартным отклонением 50000.
Известно, что доходы 40 % семей меньше величины A
. Найти величину A
. Решение. В этой задаче 40 % - ни что иное, как вероятность того, что случайная величина
примет значение из открытого интервала, меньшее определённого значения, обозначенного буквой A
. Чтобы найти величину A
, сначала составим интегральную функцию: По условию задачи μ
= 300000
- среднее значение; σ
= 50000
- стандартное отклонение; x
= A
- величина, которую нужно найти. Составляем равенство По статистическим таблицам находим, что вероятность 0,40 соответствует значению
границы интервала z
= −0,25
. Поэтому составляем равенство и находим его решение: A
= 287300
. Ответ: доходы 40 % семей менее 287300. Во многих задачах требуется найти вероятность того, что нормально распределённая
случайная величина примет значение в интервале от z
1
до z
2
.
То есть попадёт в закрытый интервал. Для решения таких задач необходимо найти в таблице вероятности,
соответствующие границам интервала, а затем найти разность этих вероятностей. При этом требуется вычитать
меньшее значение из большего. Примеры на решения этих распространённых задач - следующие, причём решить их предлагается самостоятельно,
а затем можно посмотреть правильные решения и ответы. Пример 3.
Прибыль предприятия за некоторый период - случайная величина,
подчинённая нормальному закону распределения со средним значением 0,5 млн. у.е. и стандартным отклонением
0,354. Определить с точностью до двух знаков после запятой вероятность того, что прибыль предприятия составит от 0,4 до 0,6 у.е. Пример 4.
Длина изготавливаемой детали представляет собой случайную
величину, распределённую по нормальному закону с параметрами μ
=10
и
σ
=0,071
. Найти с точностью до двух знаков после запятой вероятность брака, если допустимые размеры детали
должны быть 10±0,05
. Подсказка: в этой задаче помимо нахождения вероятности попадания случайной величины
в закрытый интервал (вероятность получения небракованной детали) требуется выполнить ещё одно действие. позволяет определить вероятность того, что стандартизованное значение Z
не
меньше -z
и не больше +z
, где z
- произвольно выбранное значение стандартизованной
случайной величины. Приближенный метод проверки нормальности распределения значений выборки основан на
следующем свойстве нормального распределения: коэффициент асимметрии β
1
и коэффициент эксцесса β
2
равны нулю
. Коэффициент асимметрии β
1
численно характеризует симметрию эмпирического распределения относительно среднего. Если коэффициент
асимметрии равен нулю, то среднее арифметрического значение, медиана и мода равны:
и кривая плотности
распределения симметрична относительно среднего. Если коэффициент асимметрии меньше нуля
(β
1
< 0
),
то среднее арифметическое меньше медианы, а медиана, в свою очередь, меньше моды
() и кривая сдвинута
вправо (по сравнению с нормальным распределением)
. Если коэффициент асимметрии больше нуля
(β
1
> 0
),
то среднее арифметическое больше медианы, а медиана, в свою очередь, больше моды
() и кривая сдвинута
влево (по сравнению с нормальным распределением)
. Коэффициент эксцесса β
2
характеризует концентрацию эмпирического распределения вокруг арифметического среднего в направлении
оси Oy
и степень островершинности кривой плотности распределения.
Если коэффициент эксцесса больше нуля, то кривая более вытянута (по сравнению с нормальным распределением)
вдоль оси Oy
(график более островершинный). Если коэффициент
эксцесса меньше нуля, то кривая более сплющена (по сравнению с нормальным распределением)
вдоль оси Oy
(график более туповершинный). Коэффициент асимметрии можно вычислить с помощью функции MS Excel СКОС. Если вы
проверяете один массив данных, то требуется ввести диапазон данных в одно окошко "Число". Коэффициент эксцесса можно вычислить с помощью функции MS Excel ЭКСЦЕСС. При проверке
одного массива данных также достаточно ввести диапазон данных в одно окошко "Число". Итак, как мы уже знаем, при нормальном распределении коэффициенты асимметрии и эксцесса
равны нулю. Но что, если мы получили коэффициенты асимметрии, равные -0,14, 0,22, 0,43, а коэффициенты
эксцесса, равные 0,17, -0,31, 0,55? Вопрос вполне справедливый, так как практически мы имеем дело лишь с
приближенными, выборочными значениями асимметрии и эксцесса, которые подвержены некоторому неизбежному,
неконтролируемому разбросу. Поэтому нельзя требовать строгого равенства этих коэффициентов нулю, они
должны лишь быть достаточно близкими к нулю. Но что значит - достаточно? Требуется сравнить полученные эмпирические значения с
допустимыми значениями. Для этого нужно проверить следующие неравенства (сравнить значения коэффициентов
по модулю с критическими значениями - границами области проверки гипотезы). Для коэффициента асимметрии β
1
. Случайная величина Х
имеет нормальное распределение (или распределение по закону Гаусса), если ее плотность вероятности имеет вид: Рис. 2.13 Рис. 2.14 ,
,![]()
Вероятность попадания значения нормально распределённой случайной величины в заданный интервал
 .
.![]() .
.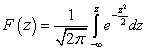 .
.
Открытый интервал
![]() .
.![]()
![]() .
.![]()
Закрытый интервал

Приближенный метод проверки нормальности распределения


,
где параметры а
– любое действительное число и σ >0.
График дифференциальной функции нормального распределения называют нормальной кривой (кривой Гаусса). Нормальная кривая (рис. 2.12) симметрична относительно прямой х
=а
, имеет максимальную ординату , а в точках х
= а
± σ – перегиб.
Рис. 2.12
Доказано, что параметр а
является математическим ожиданием (также модой и медианой), а σ – средним квадратическим отклонением. Коэффициенты асимметрии и эксцесса для нормального распределения равны нулю:As
= Ex
= 0.
Установим теперь, как влияет изменение параметров а
и σ на вид нормальной кривой. При изменении параметра а
форма нормальной кривой не изменяется. В этом случае, если математическое ожидание (параметр а
) уменьшилось или увеличилось, график нормальной кривой сдвигается влево или вправо (рис. 2.13).
При изменении параметра σ изменяется форма нормальной кривой. Если этот параметр увеличивается, то максимальное значение функции убывает, и наоборот. Так как площадь, ограниченная кривой распределения и осью Ох
, должна быть постоянной и равной 1, то с увеличением параметра σ кривая приближается к оси Ох
и растягивается вдоль нее, а с уменьшением σ кривая стягивается к прямой х
= а
(рис. 2.14).
Функция плотности нормального распределения φ(х
) с параметрами а
= 0, σ = 1 называется плотностью стандартной нормальной случайной величины
, а ее график – стандартной кривой Гаусса.
Функция плотности нормальной стандартной величины определяется формулой , а ее график изображен на рис. 2.15.
Из свойств математического ожидания и дисперсии следует, что для величины , D(U
)=1, M
(U
) = 0. Поэтому стандартную нор мальную кривую можно рассматривать как кривую распределения случайной величины , где Х
– случайная величина, подчиненная нормальному закону распределения с параметрами а
и σ.
Нормальный закон распределения случайной величины в интегральной форме имеет вид
(2.10)
Полагая в интеграле (3.10) , получим
,
где . Первое слагаемое равно 1/2 (половине площади криволинейной трапеции, изображенной на рис. 3.15). Второе слагаемое
(2.11)
называется функцией Лапласа
, а также интегралом вероятности.
Поскольку интеграл в формуле (2.11) не выражается через элементарные функции, для удобства расчетов составлена для z
≥ 0 таблица функции Лапласа. Чтобы вычислить функцию Лапласа для отрицательных значений z
, необходимо воспользоваться нечетностью функции Лапласа: Ф(–z
) = – Ф(z
). Окончательно получаем расчетную формулу
Отсюда получаем, что для случайной величины Х
, подчиняющейся нормальному закону, вероятность ее попадания на отрезок [ α, β] есть
(2.12)
С помощью формулы (2.12) найдем вероятность того, что модуль отклонения нормального распределения величины Х
от ее центра распределения а
меньше 3σ. Имеем
Р(|x
– a
| < 3 s) =P(а
–3 s< X
< а
+3 s)= Ф(3) – Ф(–3) = 2Ф(3) »0,9973.
Значение Ф(3) получено по таблице функции Лапласа.
Принято считать событие практически достоверным
, если его вероятность близка к единице, и практически невозможным, если его вероятность близка к нулю.
Мы получили так называемое правило трех сигм
: для нормального распределения событие (|x
–a
| < 3σ) практически достоверно.
Правило трех сигм можно сформулировать иначе: хотя нормальная случайная величина распределена на всей оси х
, интервал ее практически возможных значений есть
(a
–3σ, a
+3σ)
.
Нормальное распределение имеет ряд свойств, делающих его одним из самых употребительных в статистике распределений.
Если предоставляется возможность рассматривать некоторую случайную величину как сумму достаточно большого числа других случайных величин, то данная случайная величина обычно подчиняется нормальному закону распределения. Суммируемые случайные величины могут подчиняться каким угодно распределениям, но при этом должно выполняться условие их независимости (или слабой независимости). Также ни одна из суммируемых случайных величин не должна резко отличаться от других, т.е. каждая из них должна играть в общей сумме примерно одинаковую роль и не иметь исключительно большую по сравнению с другими величинами дисперсию.
Этим и объясняется широкая распространенность нормального распределения. Оно возникает во всех явлениях, процессах, где рассеяния случайной изучаемой величины вызывается большим количеством случайных причин, влияние каждой из которых в отдельности на рассеяние ничтожно мало.
Большинство встречающихся на практике случайных величин (таких, например, как количества продаж некоторого товара, ошибка измерения; отклонение снарядов от цели по дальности или по направлению; отклонение действительных размеров деталей, обработанных на станке, от номинальных размеров и т.д.) может быть представлено как сумма большого числа независимых случайных величин, оказывающих равномерно малое влияние на рассеяние суммы. Такие случайные величины принято считать нормально распределенными. Гипотеза о нормальности подобных величин находит свое теоретическое обоснование в центральной предельной теореме и получила многочисленные практические подтверждения.
Представим себе, что некоторый товар реализуется в нескольких торговых точках. Из–за случайного влияния различных факторов количества продаж товара в каждой точке будут несколько различаться, но среднее всех значений будет приближаться к истинному среднему числу продаж.
Отклонения числа продаж в каждой торговой точке от среднего образуют симметричную кривую распределения, близкую к кривой нормального распределения. Любое систематическое влияние какого-либо фактора проявится в асимметрии распределения.
Задача
. Случайная величина распределена нормально с параметрами а
= 8, σ = 3.Найти вероятность того, что случайная величина в результате опыта примет значение, заключенной в интервале (12,5; 14).
Решение
. Воспользуемся формулой (2.12). Имеем
Задача
. Число проданного за неделю товара определенного вида Х
можно считать распределенной нормально. Математическое ожидание числа продаж
тыс. шт. Среднее квадратическое отклонение этой случайной величины σ = 0,8 тыс. шт. Найти вероятность того, что за неделю будет продано от 15 до 17 тыс. шт. товара.
Решение.
Случайная величина Х
распределена нормально с параметрами а
= М(Х
) = 15,7; σ = 0,8. Требуется вычислить вероятность неравенства 15 ≤ X
≤ 17. По формуле (2.12) получаем
